Composite Models in PowerBI -- The solution to poor search performance in SSAS
I've been working in and around SQL for over 3 decades.
I am currently working on making our business intelligence systems self-driven by using an event-based architecture. This involves providing curated data in some of the largest SQL Azure Analysis Services cubes ever built (over 6 billion records in 1 table alone).
I've developed several APIs leveraging a serverless Azure architecture to provide real-time data to various internal processes and projects.
Currently working on Project Dormouse; Durable select messaging queue that enables polling processes to extract specific messages.
With the release of composite models in PowerBI, I’ve been able to solve a long-standing issue with SQL Server Analysis Services: text search performance. In this article I am going to use our Azure Hyperscale instance (but any Microsoft SQL Server instance will do) to replace our ‘Filter’ or search tables. I’ll go into some background on how we architect our SSAS tabular models, how to ‘inject’ the new SQL Server search tables, and more importantly the SQL Server specific techniques used to overcome the DAX pushed by PowerBI.
To improve performance in our tabular models we extract the distinct values for various columns the users will be filtering/searching on into their own table in the tabular model. Some of the text-based tables are author names, titles, BISAC codes, and search terms. We will be using search terms in this tutorial.
Unlike many industries where data is locked behind IDs (users, products, locations, etc), in publishing much of the data is locked behind text (words); lots of words. Here are the statistics of the table:
- 87.5 million records
Structure:
keyword nvarchar(400) not null ID Bigint not null
select count(*)
from searchterms
where CHARINDEX(keyword,'cookbook')>=1
Now that we have some insight into the data and how the data is being used, let’s look at the technique I use to improve the overall performance. I realized that using Charindex meant that SQL Server wouldn’t be able to use an index to find the records, but I needed to put an index on the ID column to allow us to link back to SSAS. I was curious to see if there was any performance impact in scanning the the index vs a heap table and while clicking through SSMS I saw this gem from long ago.
We are running a Hyperscale Azure SQL Server so storage is not an issue (100TB max database), however I thought this might work well given how SQL Server works; at the page level.
If I want a single record or every record on the page, SQL Server must read that page into memory. This means the only way to improve the performance of searching every page is to reduce the overall number of pages. The only way to do that is to compress the data to fit more into a single page, so we will be trading I/O for CPU. I was optimistic that performance of the compression algorithm and general increase in processor power (over I/O speeds) would provide a net benefit and I was right, sort of. Below is a graph of a quick test I did.
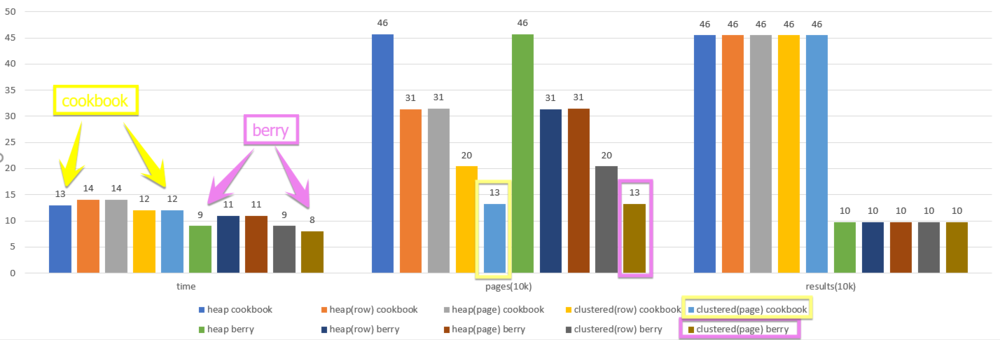
As you can see from the chart, the overall time for the queries stayed relative stable, but the number of pages change dramatically. This tells me that the work being done is in the CPU to compare those characters. Adding compression seemed to have no impact on the overall process, but it reduced the I/O load on the server by a factor of 3.5. This is good news as it allows for more queries and while I was hoping for greater speed, the timings here are much faster than those obtained while searching inside of SSAS. This also reduces the load on SSAS by shifting text searching out.
When you wire up SQL Server and SSAS the underlying queries between both parties look just like someone used app filters to pass direct values. Below is an image of what happens after the ISBNs are selected based upon a keyword search in SQL Server. This is as efficient as it can be.
I hope this article has given you some insight into how composite models can connect SQL Server and SSAS to overcome limitations of the product and inspire you to organize your data in a new way.




